Anvendelse av NLP-teknikker på TC39s møtereferater
Sammendrag
Denne rapporten detaljerer et kodeprosjekt rettet mot å utnytte naturlig språkprossesseringsteknikker (NLP) for å ekstrahere og analysere informasjon fra TC39s møtereferater, en avgjørende del av ECMAScript-standardiseringsprosessen. Bakgrunnen gir kontekst om ECMAScript, TC39, og betydningen av møtereferater i utformingen av webutvikling. Implementeringen beskriver den omhyggelige prosessen med tekstekstraksjon og bruk av ulike NLP-teknikker, fra sentimentanalyse til semantisk rollemerking. Den resulterende datastrukturen i JSON-format gir en klar representasjon av den ekstraherte informasjonen, mens en følelsesanalysegrafikk visuelt illustrerer den følelsesmessige dynamikken innenfor forslag. Prosjektet er i tråd med et bredere mål om å forbedre åpenhet og samarbeid innenfor ECMAScript-standardiseringsprosessen, og gi utviklere en nyansert innsikt i språkendringer og komitédiskusjoner.
Introduksjon
ECMAScript-standarden står som et grunnleggende element som utvikler og vedlikeholder retningslinjene som JavaScript er bygget på. Den kontinuerlige forbedringen av ECMAScript ledes av TC39-komiteen, en viktig del innen Ecma International. Denne komiteen, som består av representanter fra ulike organisasjoner, spiller en avgjørende rolle i å forme standarden og sikre dens konsistens og tilpasningsevne på tvers av ulike implementeringer.
Fokuset for dette kodeprosjektet er å utforske teknikker innen naturlig språkprosessering (NLP) for å ekstrahere og analysere informasjon som ligger i møtereferatene til TC39-komiteen. Møtereferatene utgjør en omfattende logg over diskusjoner, beslutninger og forslag, og gjenspeiler den dynamiske utviklingen av ECMAScript-standarden.
Denne rapporten beskriver bakgrunnen for ECMAScript og TC39-komiteens rolle, og understreker betydningen av deres møtereferater for å spore språkets utvikling. Deretter går den i dybden på noen NLP-teknikker, fra følelsesanalyse til semantisk rollemerking, og belyser deres relevans for å forstå nyansene i tekstlig innhold.
Implementeringsoversikten gir en trinnvis gjennomgang av utformingen av skriptet, og forklarer hvordan tekstekstraksjon, tidsstempelidentifisering, gjenkjenning av forslagsdeler og ytringsprosessering utføres. Bruken av rammeverk som TextBlob, Universal Sentence Encoder, Yake og andre er detaljert, og viser en førsteutkasttilnærming til informasjonsekstraksjon og -analyse.
Visuell representasjon i form av "sentiment-grafer" forbedrer tolkbarheten av dataene og gir en dypere forståelse av følelsesdynamikken innenfor hvert forslag. I tillegg gir JSON-file som produseres gir en strukturert og lesbar oversikt over de prosesserte dataene, som muliggjør videre analyse eller deling av resultatene.
Relatert arbeid blir diskutert, og introduserer NLP-biblioteker som Stanza og Spacy, i tillegg til Hugging Face Sentence Transformer-modellen. Disse ressursene fungerer som referansepunkter og alternativer, og belyser mangfoldet av verktøy tilgjengelig i NLP-landskapet.
Dette prosjektet har som mål å lage et verktøy som anvender NLP-teknikker på TC39s møtereferater. Målet er å ekstrahere verdifull informasjon fra korpuset som kan gi en dypere forståelse av hvordan et forslag blir diskutert, deltakernes holdninger til det og hvordan dette endrer seg over tid.
Bakgrunn
ECMAScript
ECMA-262 er en skriptspråkspesifikasjon som fungerer som standarden JavaScript baserer seg på. Den utvikles og vedlikeholdes av Ecma International, en standardiseringsorganisasjon. ECMAS-262 gir reglene og retningslinjene et skriptspråk må følge for å anses som ECMAScript-
kompatibelt.
JavaScript er den mest kjente implementeringen av ECMAScript, men andre språk som JScript og ActionScript følger også ECMAScript-standarden. Målet med ECMA-262 er å standardisere skriptspråket for å sikre interoperabilitet og konsistens på tvers av ulike nettlesere og
miljøer.
ECMAScript-spesifikasjonen utvikler seg over tid, med nye funksjoner og forbedringer som legges til for å møte kravene fra utviklere og det skiftende landskapet for webutvikling. Hver versjon av ECMAScript introduserer nye funksjoner, forbedringer og feilrettinger. Utviklere refererer ofte til de ulike versjonene av ECMAScript med utgavenummeret, som ECMAScript 6 (ES6) eller ECMAScript 2015, som brakte betydelige forbedringer til språket. Påfølgende utgaver, som ECMAScript 2016, ECMAScript 2017 og så videre, har fortsatt å bygge på standarden. Den nyeste på skrivingstidspunktet er den 14. utgaven, ECMAScript 2023.
TC39-komiteen
TC39 (Technical Committee 39) er en komité innen Ecma International som er ansvarlig for standardiseringen av programmeringsspråket ECMAScript. TC39s hovedmål er å utvikle, vedlikeholde og videreutvikle ECMAScript-standarden.
TC39 består av representanter fra ulike organisasjoner, inkludert nettleserleverandører, språkutviklere, interesseparter fra programvareutviklingsmiljøet og akademia. Komiteen samarbeider om å foreslå og diskutere nye funksjoner, forbedringer og endringer i ECMAScript.
Prosessen med å introdusere en ny funksjon eller modifisere en eksisterende funksjon, involverer vanligvis flere stadier innen TC39:
Trinn 0: Et innledende forslag eller idé blir presentert som en stråmann. Dette er et
uformelt trinn for å få tilbakemelding og innledende tanker fra komiteen.Trinn 1: Forslaget formaliseres, og den overordnede designen og
motivasjonen blir presentert for komiteen. Hvis det blir akseptert, går det videre til
neste trinn.Trinn 2: Forslaget blir ytterligere raffinert, og en foreløpig spesifikasjon
blir laget. Dette trinnet innebærer mer detaljerte diskusjoner og samarbeid
om den foreslåtte funksjonen.Trinn 3: Forslaget anses som ferdig funksjon-komplett, og en komplett
spesifikasjon er levert. På dette trinnet er det klart for innledende testing og
tilbakemelding fra "implementatører".Trinn 4: Forslaget har mottatt tilbakemelding, har blitt testet og er
klart til å bli inkludert i ECMAScript-standarden. Når komiteen
når enighet, blir funksjonen lagt til i standarden.
TC39-komiteen spiller en avgjørende rolle i den pågående utviklingen og forbedringen av ECMAScript, og sikrer at språket utvikler seg for å møte behovene til utviklere og det skiftende landskapet for webutvikling. Komiteens arbeid har en direkte innvirkning på funksjonene og mulighetene tilgjengelig for utviklere når de skriver JavaScript eller andre språk basert på ECMAScript.
Møtereferater
TC39-møtereferatene er dokumenter som oppsummerer diskusjonene, beslutningene og utfallene fra komiteens møter. Disse referatene gir en detaljert logg over hva som ble diskutert i et bestemt møte, inkludert forslag til nye språkfunksjoner, endringer i ECMAScript-standarden og andre relevante emner.
Her er noen nøkkelpunkter om disse møtereferatene:
Agenda og emner: Møtereferatene inkluderer vanligvis en agenda som
skisserer emnene som skal diskuteres i løpet av møtet. Dette kan inkludere
spesifikke forslag til nye språkfunksjoner, oppdateringer på eksisterende forslag,
diskusjoner om språkdesignprinsipper og mer.Deltakere: Referatene lister ofte opp deltakerne som var til stede på
møtet, inkludert representanter fra ulike organisasjoner, språkutviklere
og interesseparter. Dette gir åpenhet om hvem som bidrar til diskusjonene.Diskusjon og beslutninger: For hvert agendapunkt oppsummerer referatene
diskusjonene som fant sted. Dette inkluderer synspunktene som ble uttrykt av
ulike deltakere, potensielle bekymringer og eventuelle beslutninger eller utfall
som komiteen kom frem til. Det gir innsikt i resonnementet bak
beslutningene som ble tatt på møtet.Forslagsoppdateringer: Hvis det er oppdateringer på spesifikke språkforslag
(funksjoner som vurderes for inkludering i ECMAScript), vil møtereferatene belyse disse oppdateringene. Dette kan inkludere fremskritt til et høyere trinn i forslagsprosessen eller endringer basert på mottatt tilbakemelding.Handlinger og neste steg: Referatene inkluderer ofte handlingspunkter og neste
steg som oppstår fra diskusjonene. Disse kan involvere videre forskning,
adressering av bekymringer eller klargjøring av materiell til neste møte.Lenker til materiell: Møtereferatene kan inkludere lenker til tilleggsmaterialer,
som presentasjonslysbilder, dokumenter eller eksterne referanser
som ble diskutert under møtet.
Ved å gjennomgå disse møtereferatene kan utviklere, implementatører og andre interesserte parter holde seg oppdatert om den pågående innsatsen til TC39- komiteen. Det gir det bredere miljøet mulighet til å forstå rasjonalet bak språkendringer, spore fremdriften til spesifikke forslag og gi tilbakemelding på den utviklende ECMAScript-standarden.
Markdown-filer
I GitHub-kodevelvet, i rotmappen, kan det være ulike filer og mapper knyttet til TC39-prosjektet. Blant dem er det en dedikert mappe hvor møtereferater er lagret, kalt "meetings".
Denne mappen inneholder mapper som representerer hver måned og hvert år hvor det har vært et møte, noe som betyr én mappe for hver andre måned siden mai 2012. I hver av disse mappene finnes møtereferatene, samt andre relevante filer for møtet, som toc.md og summary.md.
For dette prosjektet er det imidlertid kun møtereferatene selv som er relevante.
Formatering av møtereferatene
Møtereferatene er formatert på en slik måte at hver ytring kan knyttes til en bestemt person. På denne måten kan hva hver person bidrar med til det aktuelle forslaget, lett skilles fra de andre personene involvert i møtet. Det kan brytes ned på følgende måte:
Talers akronym: Det tretegns-akronymet i starten av hver
linje representerer identifikatoren til personen som snakker. Disse akronymene er
vanligvis unike for hver deltaker og brukes konsekvent gjennom hele
møtereferatet.Kolon (:) separator: Kolonet fungerer som en separator mellom
talerens akronym og innholdet i ytringen deres. Det
skiller visuelt taleren fra kommentaren.Ytringens innhold: Etter kolonet presenteres selve innholdet i det
personen sier. Dette er essensen av deltakerens
bidrag til diskusjonen, og kan inkludere uttalelser, spørsmål,
forslag, bekymringer eller andre relevante kommentarer.
Her er et eksempel fra feb-01.md i mappen 2023-01:
ABC: Just a note to SYG to follow up with offline and to everyone interested in implementing this and trying implementation...
DEF: Ephemeron collection.
ABC: Thank you. I was trying to remember the word. By doing the transpose thing, the case that needs to be cheap becomes cheap.
DEF: So there are a couple different implementation strategies. Trade off, the big O notation of the run, the get, or the wrap. (...)
I dette eksempelet er ABC og DEF tretegns-akronymer som representerer ulike deltakere. Etter kolonet presenterer hver linje innholdet i deltakerens ytring eller kommentar.
Et overblikk over NLP-teknikker
Sentimentanalyse er en naturlig språkprossesseringsteknikk utviklet
for å oppdage og kvantifisere den følelsesmessige tonen uttrykt i en tekst,
vanligvis kategorisert som positiv, negativ eller nøytral stemning. Denne
prosessen involverer bruk av maskinlæringsalgoritmer for å analysere
ord og uttrykk innenfor en kontekst, samtidig som det tas hensyn til språklige nyanser og
variasjoner. Følelsesanalyse er særlig verdifull i næringslivet
for å vurdere kundetilfredshet gjennom anmeldelser og sosiale medier-kommentarer. I tillegg bidrar det til å overvåke den offentlige stemningen rundt
produkter, tjenester eller merker, slik at organisasjoner kan ta informerte
beslutninger basert på de rådende holdningene blant målgruppen.
(Devopedia. 2022.)Gjenkjenning av navngitte enheter (NER) er en viktig komponent innen
informasjonsekstraksjon i naturlig språkprosessering. Det innebærer
å identifisere og klassifisere enheter som navn på personer, organisasjoner,
steder, datoer og andre spesifikke termer innenfor en gitt tekst. NER-
systemer bruker maskinlæringsalgoritmer som er trent på
annoterte datasett for nøyaktig å lokalisere og kategorisere disse enhetene.
Anvendelser av NER spenner fra å ekstrahere strukturert informasjon fra
ustrukturert tekst, forbedre søkemotorers kapasiteter, til å muliggjøre
spørsmål-svar-systemer ved å identifisere nøkkelenheter i et dokument.
(Devopedia. 2020.)Semantisk rollemerking (SRL) er en oppgave innen semantisk parsering som
fokuserer på å forstå relasjonene mellom ulike elementer i en setning
ved å tildele spesifikke roller til ord eller fraser, som å identifisere
agenten, pasienten eller mottakeren i en gitt handling. Denne teknikken går
utover tradisjonell syntaktisk parsering for å fange den dypere meningen
og rollene til hver komponent i en setning. SRL er avgjørende i
oppgaver som krever en nyansert forståelse av naturlig språk, inkludert
maskinoversettelse, spørsmål-svar og følelsesanalyse, hvor det er avgjørende å
forstå rollene til enhetene for nøyaktig tolkning.
(Devopedia. 2020.)Ordklassemerking POS-tagging, tildele ordklassetagger
til ord, håndterer flertydighet i naturlig språkprosessering ved å løse
flere meninger basert på kontekst. Opprinnelig lingvistisk, gikk POS-taggere
over til en statistisk tilnærming hvor modeller oppnår over 97%
nøyaktighet. Dette forprosesseringstrinnet er grunnleggende i NLP og støtter
applikasjoner som informasjonsgjenfinning, navngitt enhetsgjenkjenning og
talesystemer. (Devopedia. 2019.)Tekstoppsummering er en tekstbehandlingsteknikk som tar sikte på å destillere
den essensielle informasjonen fra et dokument samtidig som den kjernebetydningen beholdes.
Det finnes to hovedtyper oppsummering: uttrekkende som
velger og kombinerer eksisterende setninger, og abstraherende som genererer
nye setninger for å formidle det oppsummerte innholdet. Oppsummering finner
anvendelse i nyhetsartikler, forskningsrapporter og dokumenthåndtering,
og gir en konsis oversikt over omfattende tekster og bidrar til informasjonsgjenfinning og beslutningstaking. (Devopedia. 2020)Semantisk likhet kvantifiserer likheten mellom to tekstdeler
basert på deres mening heller enn kun å støtte seg på leksikalsk eller syntaktisk
likhet. Disse målene tar hensyn til kontekst, semantikk og
relasjoner mellom ord, noe som muliggjør en mer nyansert forståelse av
likhet. Semantisk likhet anvendes i ulike NLP-oppgaver, inkludert
duplikatdeteksjon, dokumentgruppering og anbefalingssystemer.
Ved å fange den underliggende meningen i tekst, forbedrer semantisk likhet
nøyaktigheten og relevansen i systemer som krever paring eller gruppering
av tekstlig informasjon. (Harispe et al., 2015)Nøkkelordekstraksjon innebærer å identifisere og ekstrahere de mest
relevante og signifikante ordene eller frasene fra en gitt tekst. Denne prosessen
bidrar til å destillere de sentrale temaene, emnene eller konseptene innenfor et dokument,
og muliggjør en mer konsis representasjon av dets innhold. NLP-algoritmer
bruker ulike teknikker, som statistisk analyse, naturlig språkprosessering
og maskinlæring, for å bestemme ordenes viktighet
basert på deres frekvens, kontekst og relasjoner innenfor teksten.
Til syvende og sist bidrar nøkkelordekstraksjon til å oppsummere og forstå
den essensielle informasjonen som finnes i en tekstmengde. (Beliga et al., 2015)
Implementering
I dette prosjektet har jeg anvendt sentimentanalyse, semantisk likhet og nøkkelordekstraksjon på møtereferatkorpuset. For å ekstrahere relevant data og produsere plott fra møtereferatene, virket dette tilstrekkelig.
For hele dette prosjektet har jeg valgt å bruke python for implementeringen av teknikkene. Dette skyldes hovedsakelig den store mengden biblioteker som er tilgjengelige, men også økt lesbarhet for de fleste utviklere. I tillegg er det også språket jeg er mest fortrolig med.
Du kan finne koden for implementeringen i mitt GitHub-repository, som er oppført i referansene. (Engelsen, 2023).
Tekstekstraksjon
Filvalg: Skriptet bruker glob-modulen, hvilket er en python-
modul som kan brukes til å identifisere stinavn som passer til et spesifisert
mønster. Den brukes til å identifisere markdown-filer innenfor den angitte mappen,
og utelukke bestemte filer som "toc.md" eller "summary.md". Dette sikrer at
kun relevante filer vurderes for prosessering og innsnevrer
analyseomfanget.Lesing av markdown-filer: For hver markdown-fil åpner og leser
skriptet innholdet ved å bruke pythons innebygde open-funksjon og read-
metode. Den tilpassede process_markdown_file-funksjonen enkapsulerer
denne operasjonen og muliggjør ekstrahering av tekst fra individuelle markdown-
filer.Tidsstempelekstraksjon: Koden ekstraherer tidsstempler fra navn på markdown-
filer ved å bruke regulære uttrykk for å gjenkjenne mønstre som
måned-dag.md. Koden tildeler disse mønstrene til tilsvarende månedsantall
og inneværende år, og genererer nøyaktige tidsstempler for hver forslagsdel.Ekstraksjon av forslagsdeler: Innenfor hver markdown-fil
identifiserer skriptet forslagsdeler ved å bruke et regulært uttrykk
(proposal_section_pattern). re.findall-funksjonen brukes til
å ekstrahere tittler på disse forslagsdelene, slik at det dannes en liste over tittler for ytterligere prosessering.Ytring- og tekstekstraksjon: For hver forslagsdel
itererer skriptet gjennom tittellistene, og ekstraherer tilhørende tekst. Den filtrerer bort irrelevante seksjoner basert på forhåndsdefinerte kriterier ved hjelp av isDumbTitle-funksjonen. Relevant tekst ekstraheres deretter ved å dele opp markdown-teksten basert på posisjonen til tittelen.Tekstrensing: Ekstrahert forslagstekst gjennomgår rensing gjennom
regulære uttrykk, hvor uønsket informasjon som presentasjonsdetaljer og
referanser til lysbilder fjernes. Mønstre som navn til foredragsholder og lysbildereferanser blir identifisert og fjernet ved hjelp av re.sub-funksjonen,
noe som sikrer at teksten fokuserer på kjerneinnholdet.Ytring- og setningsprosessering: Skriptet prosesserer
forslagsteksten ved å dele den opp i ytringer ved hjelp av et regulært uttrykk
(utterance_pattern) for å identifisere talebidraget. Hver ytring
deles deretter inn i setninger ved hjelp av re.split-funksjonen. Setninger
prosesseres individuelt, og nøkkelordekstraksjon utføres ved hjelp av
Yake-biblioteket.
Dictionary-objekt for forslag
Dictionary-objektet for forslagene lagrer essensiell informasjon om et spesifikt
forslag som er ekstrahert fra møtereferatene. Her er en forklaring av objektets egenskaper:
title: Dette feltet lagrer tittelen på forslaget og gir en konsis
identifikator for forslagets emne.timestamp: Representerer tidsstempler assosiert med forslaget,
vanligvis ekstrahert fra navnet på markdown-filen.utterances: Dette er en liste som inneholder individuelle utterance-
ordboksobjekter. Hver ytring tilsvarer en seksjon av forslaget der en
bestemt taler bidrar.full text: Hele innholdet i forslaget er lagret her, noe som muliggjør
omfattende analyse og sammenligninger.
Utterance Dictionary-objekt
Ytringsobjektet representerer en talers bidrag til diskusjonen
som inneholder ytringen. Her er en forklaring av objektets egenskaper:
utterance_number: Det kronologiske nummeret til ytringen innen forslaget.
timestamp: Bærer tidsstempler assosiert med forslaget. Dette vil
tilsvare datoen for møtet, som er en dato oversatt fra
navnet på markdown-filen.sentences: Denne listen inneholder individuelle setningsordboksobjekter,
der hvert objekt representerer en setning innenfor ytringen.polarity: Representerer den overordnede følelsespolariteten for hele
ytringen.subjectivity: Gjenspeiler subjektiviteten til ytringen som helhet.
keywords: Lagrer nøkkelord ekstrahert fra ytringen ved hjelp av Yake-
biblioteket, og gir innsikt i hovedtemaene.
Sentence Dictionary-objekt
Setningsobjektet representerer en individuell setning innenfor en ytring.
Her er en forklaring av objektets egenskaper:
sentence_number: En unik identifikator for hver setning innenfor en
ytring.text: En streng som inneholder innholdet i den individuelle setningen.
polarity: Følelsespolariteten til setningen.
subjectivity: Subjektiviteten til setningen.
Rammeverk som er brukt
TextBlob TextBlob er et bibliotek som forenkler vanlige naturlige språkprosesseringsoppgaver. I dette skriptet brukes det for grunnleggende sentimentanalyse,
som muliggjør bestemmelse av polaritet og subjektivitet for
både setninger og hele ytringer. (Loria, 2020)Universal Sentence Encoder TensorFlows Universal Sentence Encoder
(USE) er en forhåndstrent modell som konverterer tekst til høydimensjonale
vektorer. Dette skriptet bruker USE til å generere embedding for setninger,
noe som muliggjør beregning av semantisk likhet mellom ulike tekster.
(Cer et al., 2018)Yake Yake er et nøkkelordekstraksjonsbibliotek som identifiserer signifikante
nøkkelord innen en gitt tekstbit. I dette skriptet brukes Yake til
å ekstrahere nøkkelord fra hver ytring, noe som bidrar til å forstå
hovedtemaene som blir diskutert. (Campos et al., 2020)Matplotlib Matplotlib er et plottbibliotek i Python. I dette skriptet
brukes det til å lage følelsesanalyseplotterier. Disse plottene representerer visuelt hvordan
følelser endrer seg gjennom ytringene i et forslag. (Hunter,Regulære uttrykk Regulære uttrykk brukes for mønstergjenkjenning
og ekstraksjon. I denne sammenhengen bidrar de til å identifisere spesifikke
seksjoner av markdown-filer og rense forslagstekster ved å fjerne
irrelevant informasjon som presentatørdetaljer og lysbildereferanser. (Python
Software Foundation, 2023)TensorFlow TensorFlow er et åpen kilde-maskinlæringsrammeverk,
og i dette skriptet brukes det til å laste og utnytte en forhåndstrent modell
for å kode setninger til meningsfulle vektorer. I denne koden blir det brukt
til å laste og bruke Universal Sentence Encoder-modellen. (Abadi et al.,
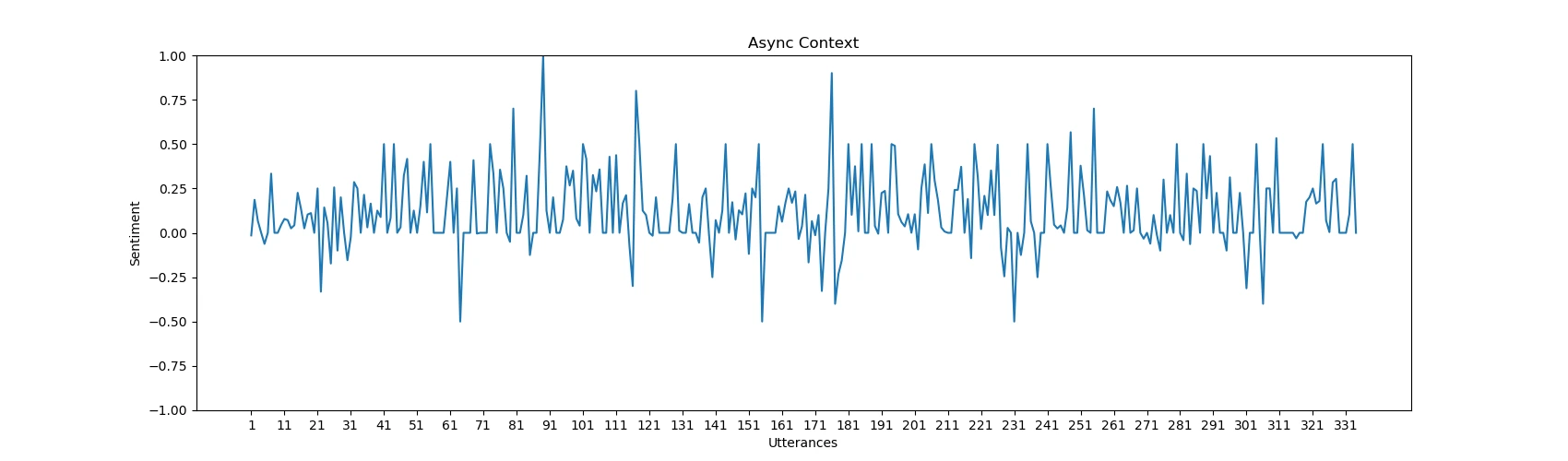
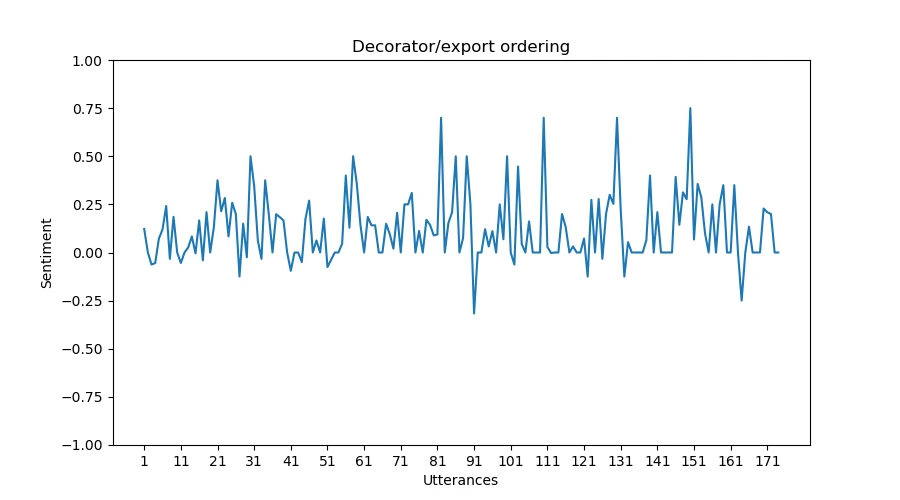
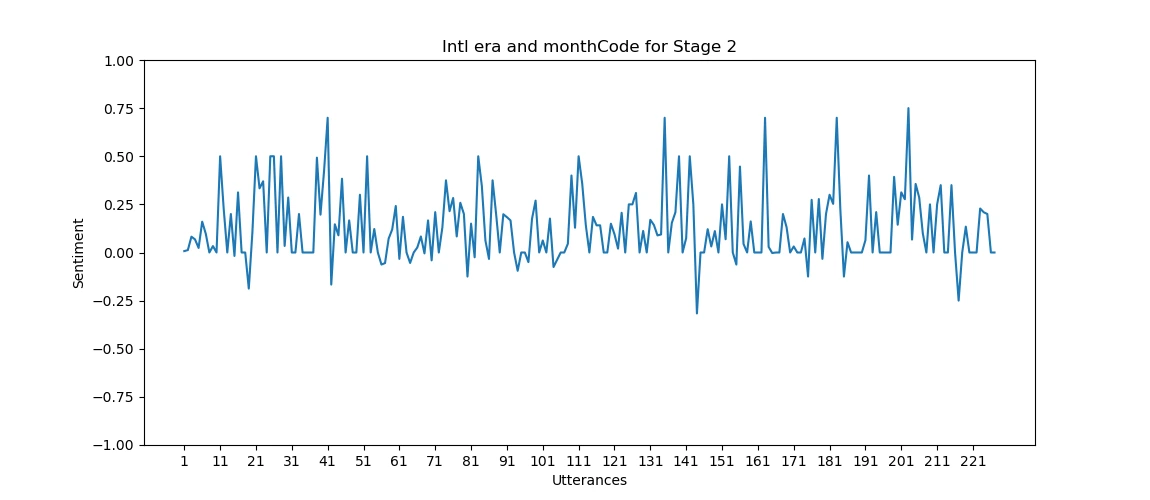
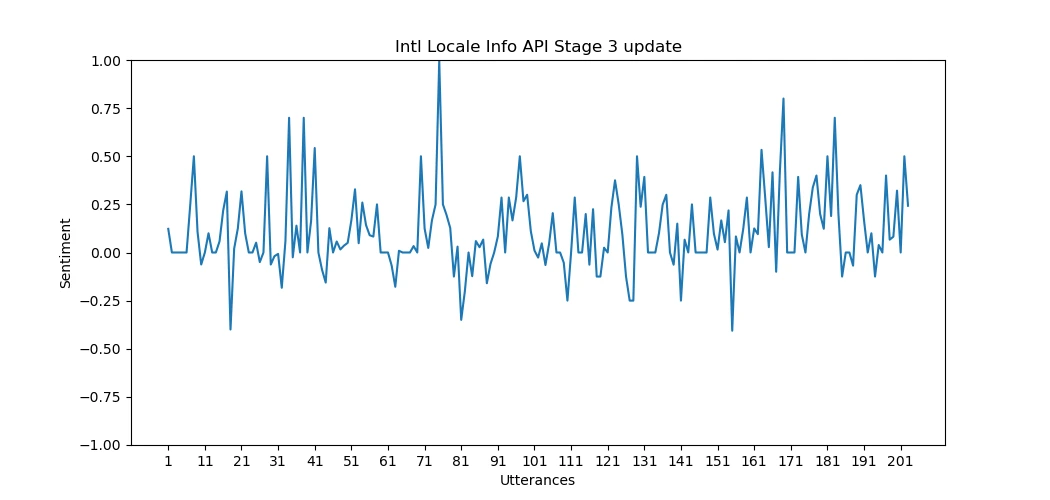
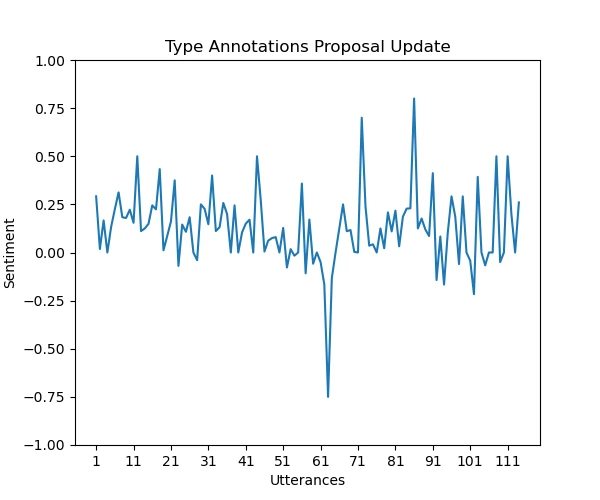
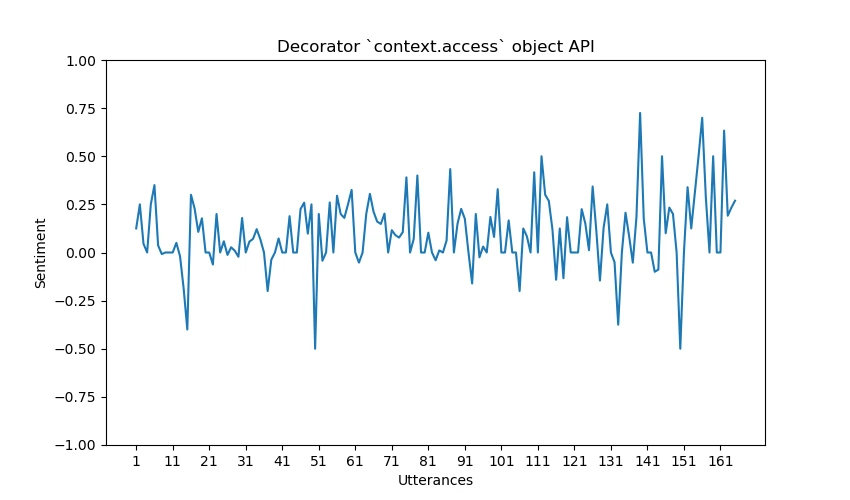
Graf for sentimentanalyse Sentimentalysediagrammet genereres ved hjelp av Matplotlib og
tjener til å visuelt illustrere følelsesdynamikken innenfor et forslag. Her er en
forklaring av grafikkegenskapene.
X-aksen: Representerer individuelle ytringer innenfor forslaget.
Y-aksen: Viser følelsespolariteten og illustrerer endringer i stemningen
fra positiv til negativ mellom -1.0 og 1.0. -1.0 betyr fullstendig
negativ, 0 betyr fullstendig nøytral og 1.0 betyr fullstendig positiv.Markeringer: Punkter på grafen markerer ytringer med spesielt
høy positiv eller negativ stemning, og gir en rask oversikt over
følelsestopper og bunnpunkter. Ytringene som er årsaken til denne toppen,
skrives ut i en JSON-fil.
For hvert forslag i proposals-listen plottes et følelsesdiagram for å visualisere
følelsen for hver ytring på det forslaget, og hvordan følelsen endrer seg
i løpet av antall ytringer.
Forslag som datastruktur i JSON-format Mot slutten av
skriptet skrives datastrukturen for hvert forslag ut i JSON-format. Denne
utdataen gir en detaljert visning av de behandlede dataene, inkludert titler,
tidsstempler, ytringer og full tekst. JSON-format er valgt for sin lesbarhet
og lette inspeksjon, noe som gjør det praktisk for videre analyse eller deling av resultatene.
Relatert arbeid
Stanford NLP (Stanza)
Stanford NLP, nå kjent som Stanza, er et robust naturlig språkprosesseringsbibliotek
utviklet av Stanford NLP-gruppen. Det tilbyr et utvalg av toppmoderne
verktøy for ulike språkprosesseringsoppgaver, inkludert tokenisering, ordklassetagging,
navngitt enhetsgjenkjenning og avhengighetsanalyse. Stanza tilbyr forhåndstrente
modeller for flere språk, noe som gjør det mulig for brukere å utføre avansert
språkanalyse med letthet. En av hovedstyrkene er den dype integrasjonen
med dype læringstekniker, som resulterer i høy nøyaktighet og effektivitet på tvers av en
rekke NLP-oppgaver. Fokuset på flerspråklig støtte gjør det til et allsidig valg
for forskere og utviklere som jobber med ulike språkdatasett. (Peng et al., 2020)
Spacy NLP
Spacy er et populært åpen kilde naturlig språkprosesseringsbibliotek designet
for effektivitet og brukervennlighet. Det utmerker seg ved å tilby rask og nøyaktig språklig
annotasjon, inkludert tokenisering, ordklassetagging, navngitt enhetsgjenkjenning og avhengighetsanalyse. Spacys strømlinjeformede API og forhåndstrente
modeller gjør det brukervennlig for både nybegynnere og erfarne utviklere. Det er kjent for sin
effektivitet, noe som muliggjør sanntidsbruk i ulike kontekster.
Spacy støtter også egendefinert modelltrening, som gjør at brukere kan tilpasse det til
domene-spesifikke språkmønstre. Samlet sett er Spacy et allsidig verktøy for NLP-
oppgaver, der det oppnår en balanse mellom ytelse og enkelhet. (Honnibal et al., 2020)
Hugging Face Sentence Transformer (all-MiniLM-L6-v2)
Hugging Face sitt Sentence Transformer-bibliotek, spesifikt modellen "all-
MiniLM-L6-v2", er en del av det bredere Transformers-biblioteket. Det er utviklet
av Hugging Face, en plattform som huser en enorm samling av forhåndstrente modeller
for naturlige språkprosesseringsoppgaver. Sentence Transformer-modellen utmerker seg
i å lage embedding-er for setninger eller tekstbiter, noe som gjør den verdifull for
oppgaver som semantisk likhet og informasjonsgjenfinning. "all-MiniLM-L6-v2"
refererer til den spesifikke arkitekturen og versjonen av MiniLM-modellen som brukes
i denne implementeringen. Hugging Face sin Transformers-bibliotek forenkler
integreringen av avanserte transformer-modeller i ulike NLP-applikasjoner,
og fremmer tilgjengelighet og innovasjon innen feltet. (Hugging Face, n.d)
Konklusjon og videre arbeid
Konklusjonen jeg kan trekke fra dette prosjektet, er at den beste tilnærmingen for å
ekstrahere brukbar data fra møtereferatene, er å bruke en kombinasjon av ulike
NLP-biblioteker og -teknikker. Å bare bruke én forhåndstrent modell er for utilstrekkelig
for formålet med dette prosjektet.
Plottene produsert av implementeringen i dette prosjektet ser ut til å ha en positiv skjevhet.
Den gjennomsnittlige følelsen fra alle plottene, ved kvalitativ måling,
kan anslås til å være mellom 0,5 og 0. Mens det er noen topper i
grafene i både negativ og positiv retning, estimerer følelsesanalysen
de fleste ytringer til å være enten nøytrale eller lett positive.
Det bør imidlertid anerkjennes at den største utfordringen med dette prosjektet
har vært å finne en måte å nøyaktig estimere hvorvidt to eller flere diskusjoner
omhandler det samme forslaget. Implementeringen i dette prosjektet er ikke
like nyansert som den kunne vært, og som et resultat kan ytringene som måles i hvert
forslag, ikke fullt ut gjenspeile den sanne utviklingen av følelser for hvert
forslag.
Kjøretid
De neste naturlige trinnene for å forbedre denne implementeringen ville være å forbedre
kjøretiden. Per nå, på en gjennomsnittlig skrivebordsdatamaskin, tar det mellom 36 og 48 timer å
lage følelsesanalysegrafer for alle forslag nevnt i møtereferatene, datert
tilbake til 2016. Etter hvert som listen over forslag i proposals-listen blir lengre, øker
kjøretiden på grunn av en akkumulering av unike elementer.
Opprinnelig hadde jeg tenkt å konkatanere fullteksten til hvert forslag som møter
likhetsterskel, for å øke nøyaktigheten til den semantiske likkalkuleringen. Skriptet stoppet til slutt på grunn av mangel på tilgjengelig
RAM.
En mulig linje å undersøke kunne være å lage oppsummeringer av fulltekstene
til hvert forslag og konkatanere disse for nøyaktig sammenligning.
Unik identifikator for hvert forslag
Den største utfordringen med dette prosjektet var hvordan man skal bestemme om to seksjoner i
møtereferatene faktisk diskuterer det samme forslaget. Tanken min var at hvis den
semantiske likheten mellom de to seksjonene er over en viss terskel,
må de snakke om det samme. Dette er imidlertid ikke nødvendigvis tilfellet.
Følgende scenario kan forekomme: Et unikt forslag blir diskutert i 2017. Senere, i 2019, blir et annet unikt forslag diskutert. Det senere forslaget
er imidlertid fullstendig avhengig av det tidligere forslaget. Diskusjonen av det
senere forslaget inneholder derfor mange referanser og diskusjoner om det
tidligere forslaget. Ved kun å evaluere semantisk likhet, ville disse to seksjonene
bli vurdert som en del av samme forslag, noe som ikke er tilfellet.
På grunn av denne typen dilemma, er en forbedret måte å estimere likhet på nødvendig
for nøyaktig å bestemme om to seksjoner er diskusjoner knyttet til
det samme forslaget.
Mitt første forslag er å gi hvert unikt forslag som blir diskutert på møtene,
en unik identifikator, f.eks. "AYD245". Så hver gang det samme forslaget
blir diskutert, blir den samme identifikatoren anvendt på seksjonen i møtereferatet. Mitt andre forslag er å bruke en ensemble av ulike NLP-teknikker for å lage en sammensatt likhetsskår. På denne måten er det mer nyanse involvert i estimeringen av likhet.
Referanser
Abadi, M., Agarwal, A., Barham, P., Brevdo, E., Chen, Z., Citro, C., Corrado, G. S., Davis, A., Dean, J., Devin, M., Ghemawat, S., Goodfellow, I., Harp, A., Irving, G., Isard, M., Jozefowicz, R., Jia, Y., Kaiser, L., Kudlur, M., Levenberg, J., Mané, D., Schuster, M., Monga, R., Moore, S., Murray, D., Olah, C., Shlens, J., Steiner, B., Sutskever, I., Talwar, K., Tucker, P., Vanhoucke, V., Vasudevan, V., Viégas, F., Vinyals, O., Warden, P., Wattenberg, M., Wicke, M., Yu, Y., & Zheng, X. (2015). TensorFlow, Storskalert maskinlæring på heterogene systemer [Datasystem]. https://doi.org/10.5281/zenodo.4724125
Campos, R., Mangaravite, V., Pasquali, A., Jatowt, A., Jorge, A., Nunes, C. og Jatowt, A. (2020). YAKE! Nøkkelordekstraksjon fra enkeltdokumenter ved hjelp av flere lokale funksjoner. I Information Sciences Journal. Elsevier, Vol 509, pp 257-289. https://doi.org/10.1016/j.ins.2019.09.013
Cer, D., Yang, Y., Kong, S.-y., Hua, N., Limtiaco, N., St. John, R., Constant, N., Guajardo-Cespedes, M., Yuan, S., Tar, C., Sung, Y.-H., Strope, B., & Kurzweil, R. (2018). Universal Sentence Encoder. arXiv preprint https://arxiv.org/pdf/1803.11175.pdf
Devopedia. 2019. "Ordklassetagging." Versjon 3, 8. september. Åpnet 12. november 2023. https://devopedia.org/part-of-speech-tagging
Devopedia. 2020. "Navngitt enhetsgjenkjenning." Versjon 5, 4. februar. Åpnet 12. november 2023. https://devopedia.org/named-entity-recognition
Devopedia. 2020. "Semantisk rollemerking." Versjon 3, 10. januar. Åpnet 12. november 2023. https://devopedia.org/semantic-role-labelling
Devopedia. 2020. "Tekstoppsummering." Versjon 2, 21. februar. Åpnet 12. november 2023. https://devopedia.org/text-summarization
Devopedia. 2022. "Følelsesanalyse." Versjon 52, 26. januar. Åpnet 12. november 2023. https://devopedia.org/sentiment-analysis
Engelsen, C. (2023). sentiment-plotter [Datasystem]. https://github.com/Cengelsen/sentiment-plotter
Harispe, S., Ranwez, S., Janaqi, S., & Montmain, J. (2015). Semantisk likhet fra naturlig språk og ontologianalyse. Synthesis Lectures on Human Language Technologies. Springer International Publishing. https://doi.org/10.1007/978-3-031-02156-5
Honnibal, M., Montani, I., Van Landeghem, S., & Boyd, A. (2020). spaCy: Industriell naturlig språkprosessering i Python. https://doi.org/10.5281/zenodo.1212303
Hunter, J. D. (2007). Matplotlib: Et 2D-grafikkmiljø. Computing in Science & Engineering, 9(3), 90–95. https://doi.org/10.1109/MCSE.2007.55
Hugging Face. (u.å.). Sentence Transformers: MiniLM-L6-v2. Hugging Face Model Hub. Hentet 18. desember 2023 fra https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2
Loria, S. (2020). TextBlob: Forenklet tekstbehandling (Versjon 0.16.0). Hentet fra https://textblob.readthedocs.io/_/downloads/en/dev/pdf/
Peng Qi, Yuhao Zhang, Yuhui Zhang, Jason Bolton og Christopher D. Manning. 2020. Stanza: Et Python-naturlig språkbehandlingsverktøy for mange menneskelige språk. I Association for Computational Linguistics (ACL) System Demonstrations. 2020. https://nlp.stanford.edu/pubs/qi2020stanza.pdf
Python Software Foundation. (2023). "re" - Regulære uttrykksoperasjoner. Python 3.11. Tilgjengelig på: https://docs.python.org/3/library/re.html
Beliga, Slobodan; Ana, Meštrović; Martinčić-Ipšić, Sanda. (2015). "Et overblikk over graf-baserte nøkkelordekstraksjonsmetoder og -tilnærminger". Journal of Information and Organizational Sciences. 39 (1): 1-20. https://hrcak.srce.hr/file/207669
Tillegg A. Følelsesanalysegrafer for forslag
Her er noen flere eksempler på grafer produsert av vår implementering.